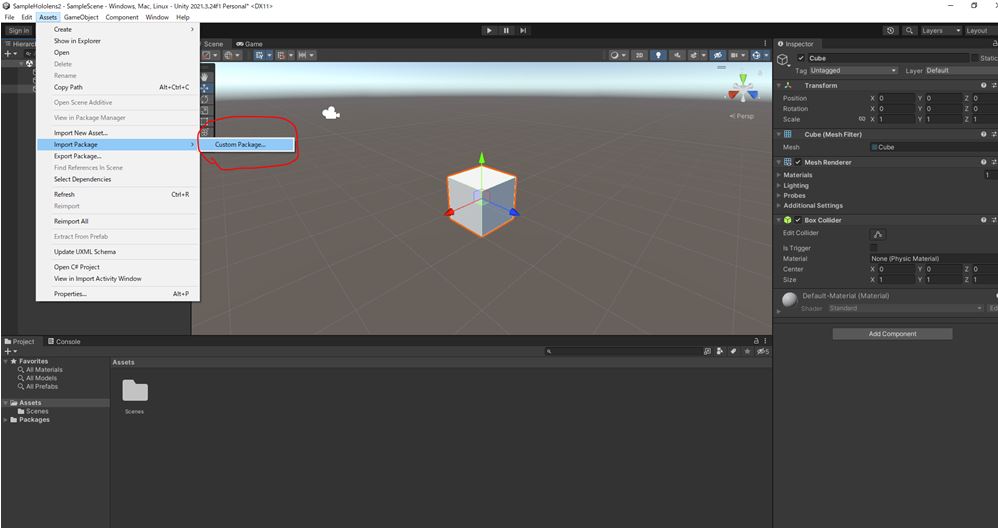
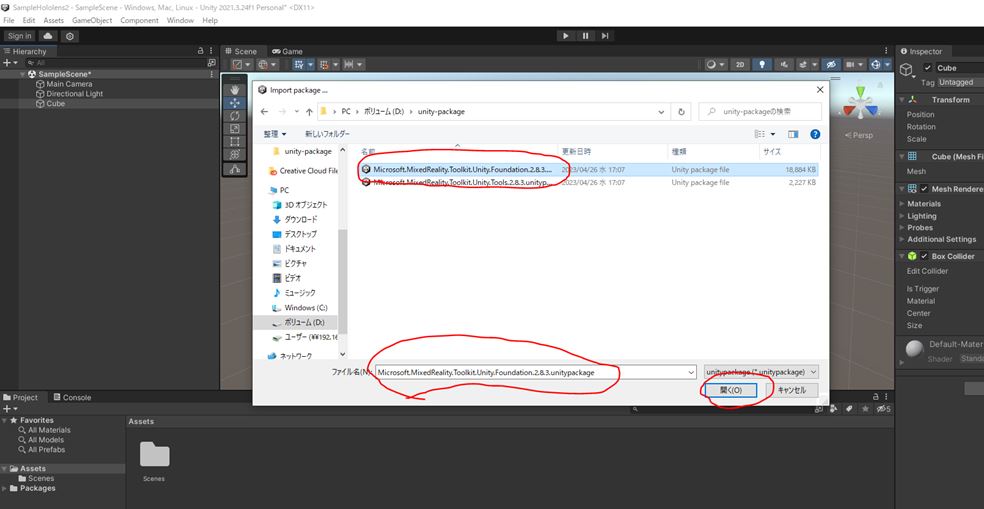
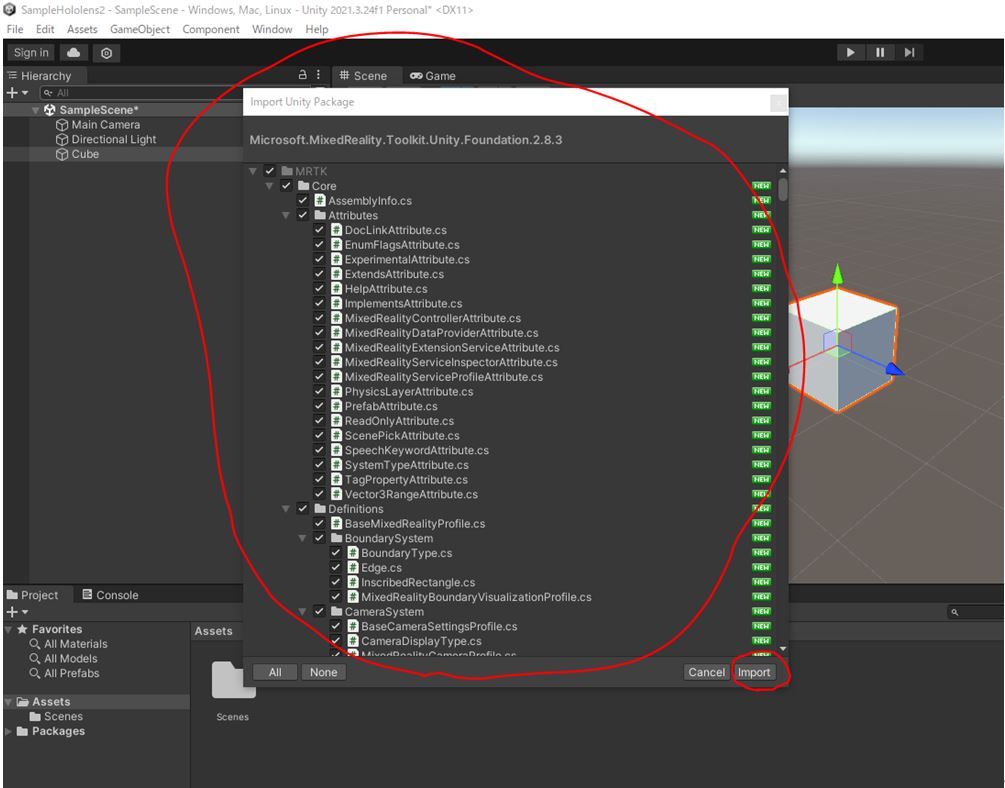
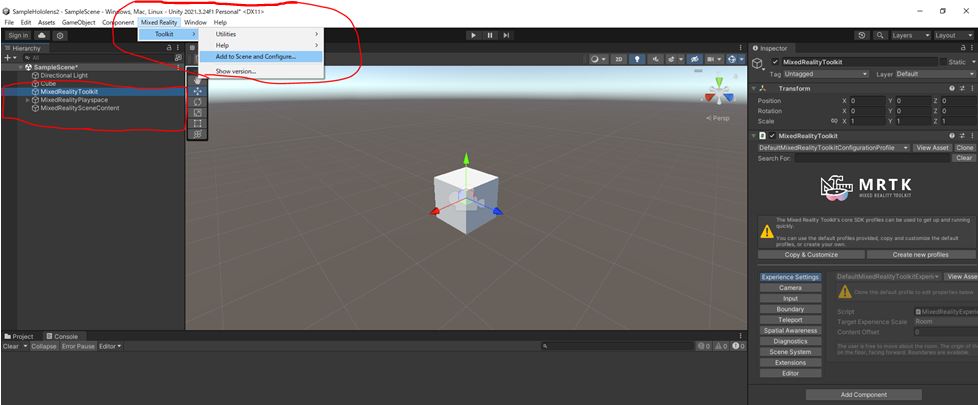
はじめに
今回はJavaを学習しているとJavaFXなるものに出会ったので備忘録を兼ねて簡単なアプリケーションを作成しながら記事をまとめていきたいと思います。
JavaFXとは
JavaFXとはJavaのフレームワークの1つで、GUIアプリケーションを作成するときに役立ちます。特徴としてXLMやCSSを利用して作成するといった点が挙げられます。
実行環境・ツール
実行環境およびツールは以下を用意・使用していきます。
・Windows11
・Eclipse 2022-12
・SceneBuilder
SceneBuilderを使用しての画面作成
ツールの用意ができたら早速画面の作成をしていきたいと思います。画面作成には「SceneBuilder」というツールを使っていきます。SceneBuilderはJavaFXで使用する画面のXMLファイルをドラッグアンドドロップで簡単に作成することができます。
ツールを起動すると空の状態から画面を作成するか、テンプレートを使用して画面を作成するかを選択できるかと思います。今回は基本アプリケーションのテンプレートを編集して画面の作成を行っていきます。
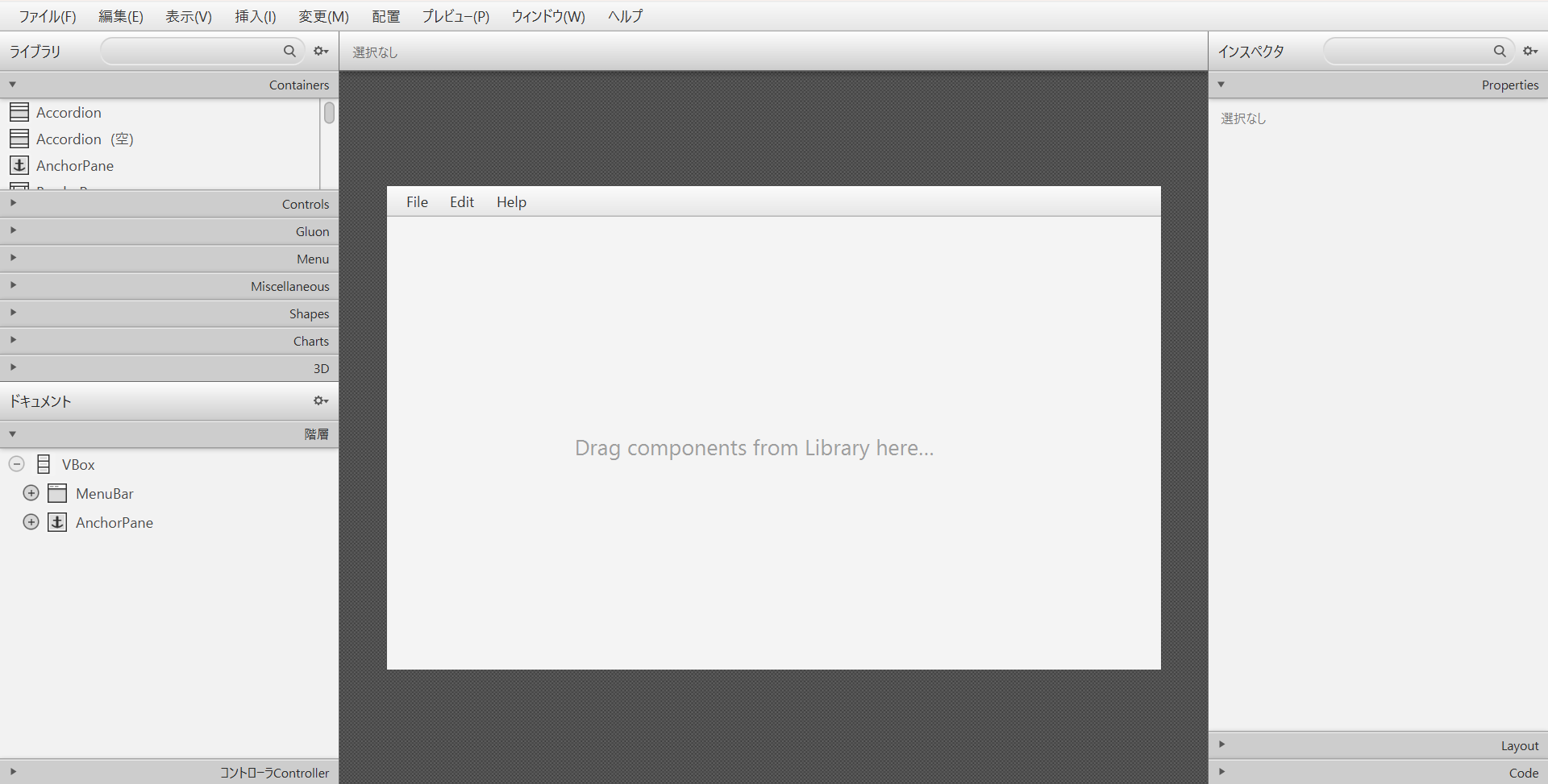
基本アプリケーションのテンプレートを選択すると上記のようにある程度編集されたされた画面が表示されます。その後、左のツールバーから必要な要素ををドラッグアンドドロップ、右のツールバーで各要素に対してIDを振り分けして画面を作成していきます。
今回は下記のような画面を作成し、「Main.fxml」という名前で保存します。
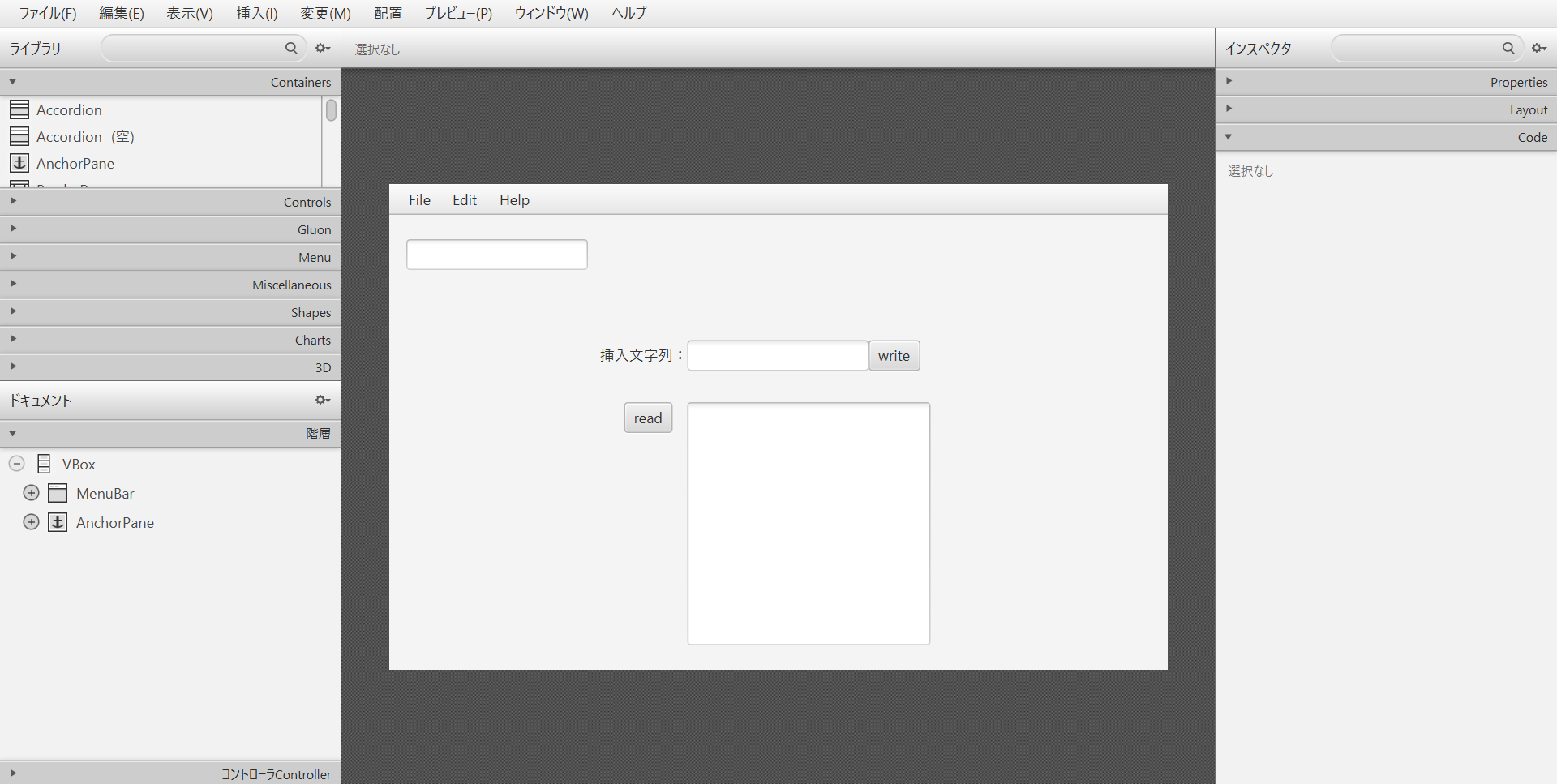
*挿入文字列のテキストフィールドに入力した文字列をSample.txtという名前のテキストファイルに挿入し、readボタンを押すとテキストファイルに記載されている文字をテキストエリアに表示するといった機能を実装していきます。左上のテキストフィールドは挿入された文字列のコンソールになります。
Eclipseプラグインの導入とプロジェクトの作成
1,Eclipseプラグインの導入
Eclipseを起動したらJavaFXプロジェクト作成のためにプラグインを導入します。ヘルプ(H)→Eclipse マーケットプレイス(M)→検索欄でJavaFXと検索→検索結果から「e(fx)clipse」というプラグインをインストールします。
2,プロジェクトの作成
プラグインのインストールが完了したらいよいよプロジェクトを作成していきます。
ファイル(F)→新規(N)→プロジェクト(R)→ウィザードの選択でJavaFX プロジェクトを選択→次へを押してプロジェクト名を入力(筆者はFxSampleという名前で作成)→次へを押してビルドの設定(後ほどやるのでそのまま次へ)→言語後をFXMLに設定し、ファイル名をMainにして完了する。
上記が完了したら以下画像のようなプロジェクトツリーができます(Main.fxmlは先ほど作成したファイルを設定してください)。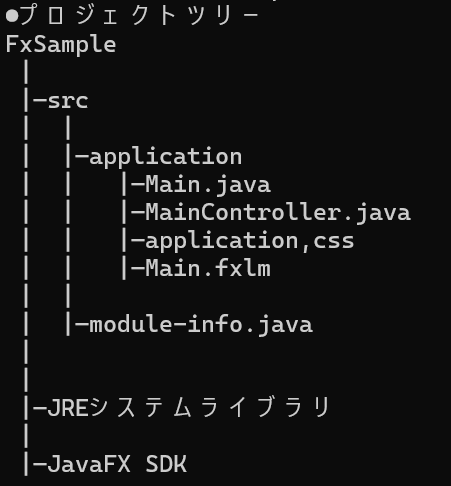
3,JavaFXモジュールのダウンロード
次にJavaFXモジュールのダウンロードを行います。ブラウザで「JavaFX」と入力すると公式サイトからダウンロードできるので最新版をダウンロードします。ダウンロードが完了したら任意のディレクトリに解凍します(後ほど必要になるので保存先を覚えておいて下さい)。
4,ビルドパスとコマンドライン引数の設定
次はビルドパスの設定を行っていきます。手順は以下となります。
プロジェクトを右クリック→ビルド・パス(B)→ライブラリの追加(L)→ユーザーライブラリ→ユーザーライブラリ(U)→新規(N)→任意の名前を設定(筆者はJavafxとして設定)→Javafxライブラリを選択し、外部jarの追加→先ほど解凍したJavaFXモジュールのlibフォルダにあるjarファイルをすべて選択→適応して完了
上記が完了するとビルドパスの設定が完了します、またコマンドライン引数を設定する前にプロジェクトディレクトリにある以下のファイル、ビルド・パスを削除しておいてください(これがあると実行時にエラーが発生します)。
・JavaFX SDK
・module-info.java
続いてコマンドライン引数の設定を行います。JavaFXにはモジュールシステムが利用されているため、使用するモジュールの設定を行わなければいけません。そのため以下の手順で設定を行います。
実行の構成を開く→プロジェクトを選択する(今回はFxSample)→引数タブを選択→VM引数に「–module-path “解凍したJavaFXフォルダ内のlibフォルダのパス” –add-modules javafx.controls,javafx.fxml」を設定
上記の設定が完了すると実行することができます。
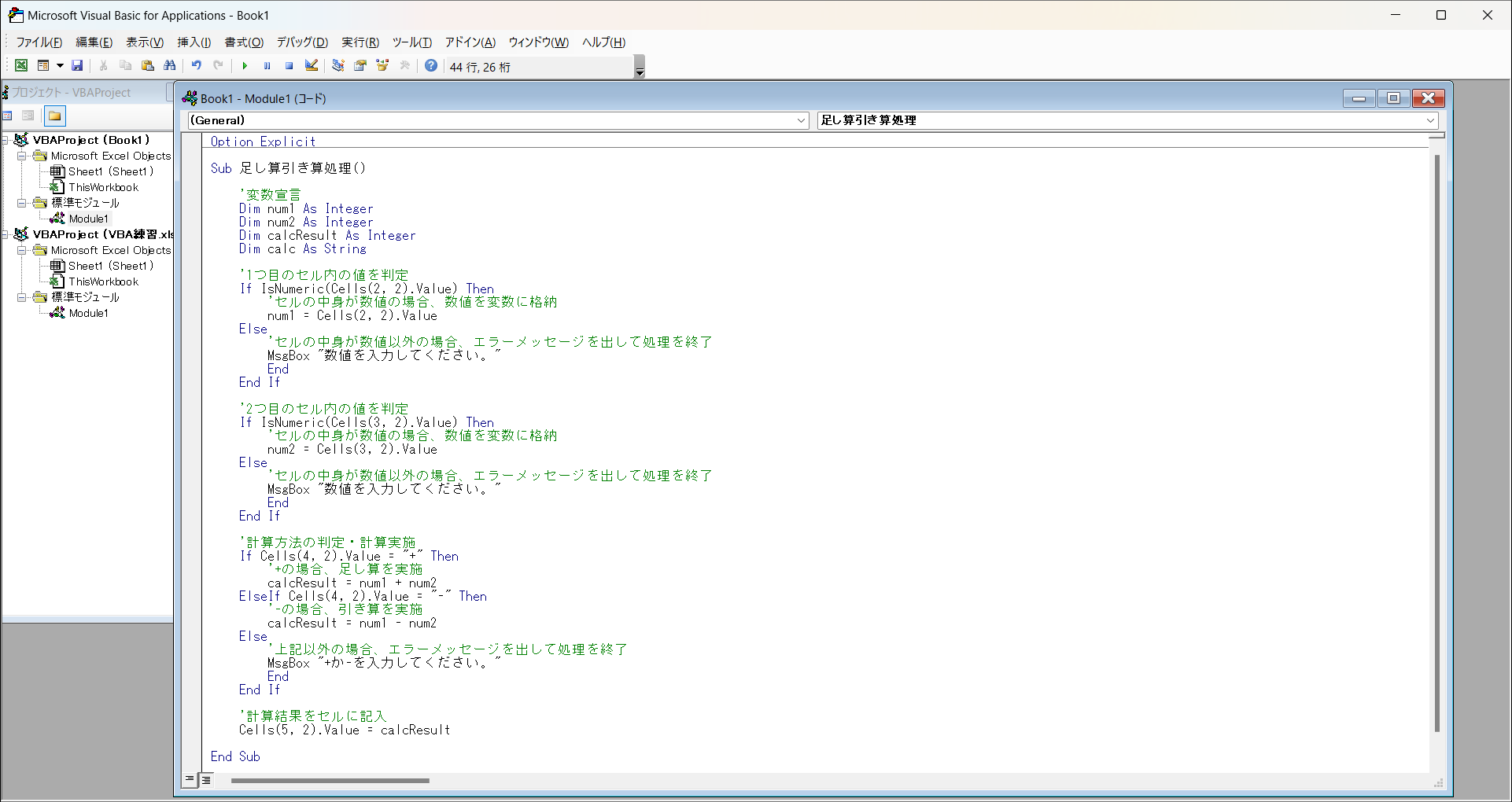
5,コーディング
設定が終わったらコーディングをしていきます。今回はapplicationディレクトリ下に以下の4つのJavaファイルを作成していきます。
・Main.java(今回は特にコーディングは行わない)
・MainController.java
・Reader.java
・Writer.java
それではコーディングを行っていきます。
Reder.java
package application;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class Reader {
public static String reader() {
String text = "";
try(BufferedReader br = new BufferedReader(new FileReader("Sample.txt"))){
String str = null;
while((str = br.readLine()) != null) {
text += str + "\n";
}
}catch(IOException e) {
}
return text;
}
}
Writer.java
package application;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class Writer {
public static void writer(String str) {
try(BufferedWriter bw =
new BufferedWriter(new FileWriter("Sample.txt",true))){
bw.write(str);
bw.newLine();
bw.flush();
}catch(IOException e){
}
}
}
MainController.java
package application;
import java.net.URL;
import java.util.ResourceBundle;
import javafx.fxml.FXML;
import javafx.fxml.Initializable;
import javafx.scene.control.Button;
import javafx.scene.control.TextArea;
import javafx.scene.control.TextField;
public class MainController implements Initializable {
@FXML
private TextField writeLabel;
@FXML
private TextField console;
@FXML
private TextArea readArea;
@FXML
private Button writeButton;
@FXML
private Button readButton;
@Override
public void initialize(URL location, ResourceBundle resources) {
// 時に記載なし
}
public void writeText() {
String wl = writeLabel.getText();
Writer.writer(wl);
writeLabel.setText("");
console.setText(wl);
}
public void readText() {
String rt = Reader.reader();
readArea.appendText(rt);;
}
}
6,実行
コーディングが終わったらいよいよ実行していきます。アプリケーションを実行するとSceneBuilderで作成した画面が表示されるかと思います。画面が表示されたら実際に文字を入力してテキストエリアに文字を表示していきたいと思います。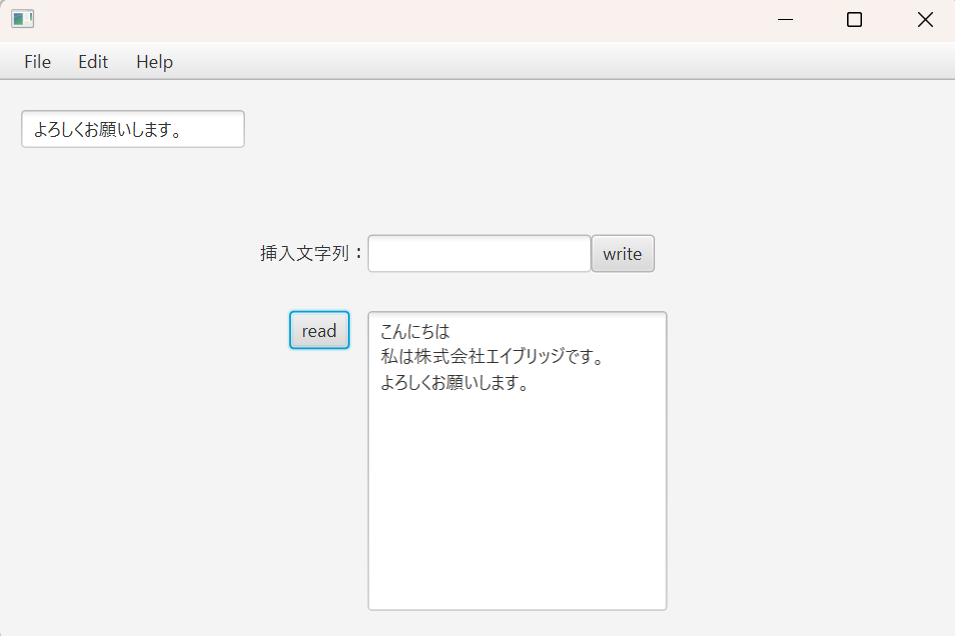 無事に文字を表示することができました。
無事に文字を表示することができました。
終わりに
今回はJavaFXアプリケーションを作成するための基礎知識をご紹介していきましたがいかがだったでしょうか。GUIアプリケーションの作成は画面の構築が面倒なイメージがありますが、画面レイアウトをツールで作成することができればかなりの作業を削減することができます。GUIアプリケーションを作成する際の選択肢の一つとしてぜひいかがでしょうか。
 上記のフォーマットは、
上記のフォーマットは、 この画面のままではまだコードの書き込みは行えないので、モジュールを追加します。
この画面のままではまだコードの書き込みは行えないので、モジュールを追加します。 次は、簡単なプログラムについて解説します。
次は、簡単なプログラムについて解説します。
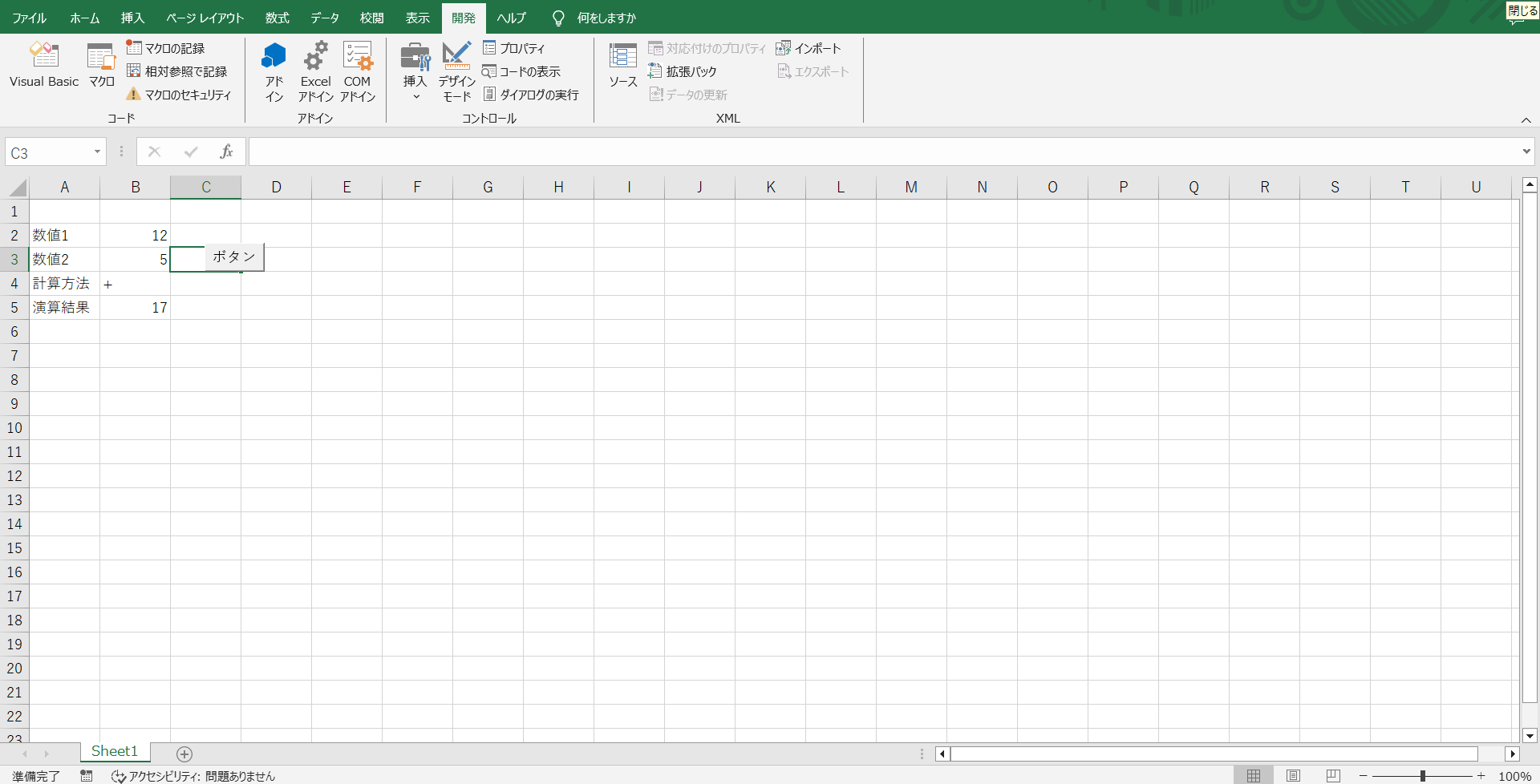 無事に計算結果である17が出力されました。
無事に計算結果である17が出力されました。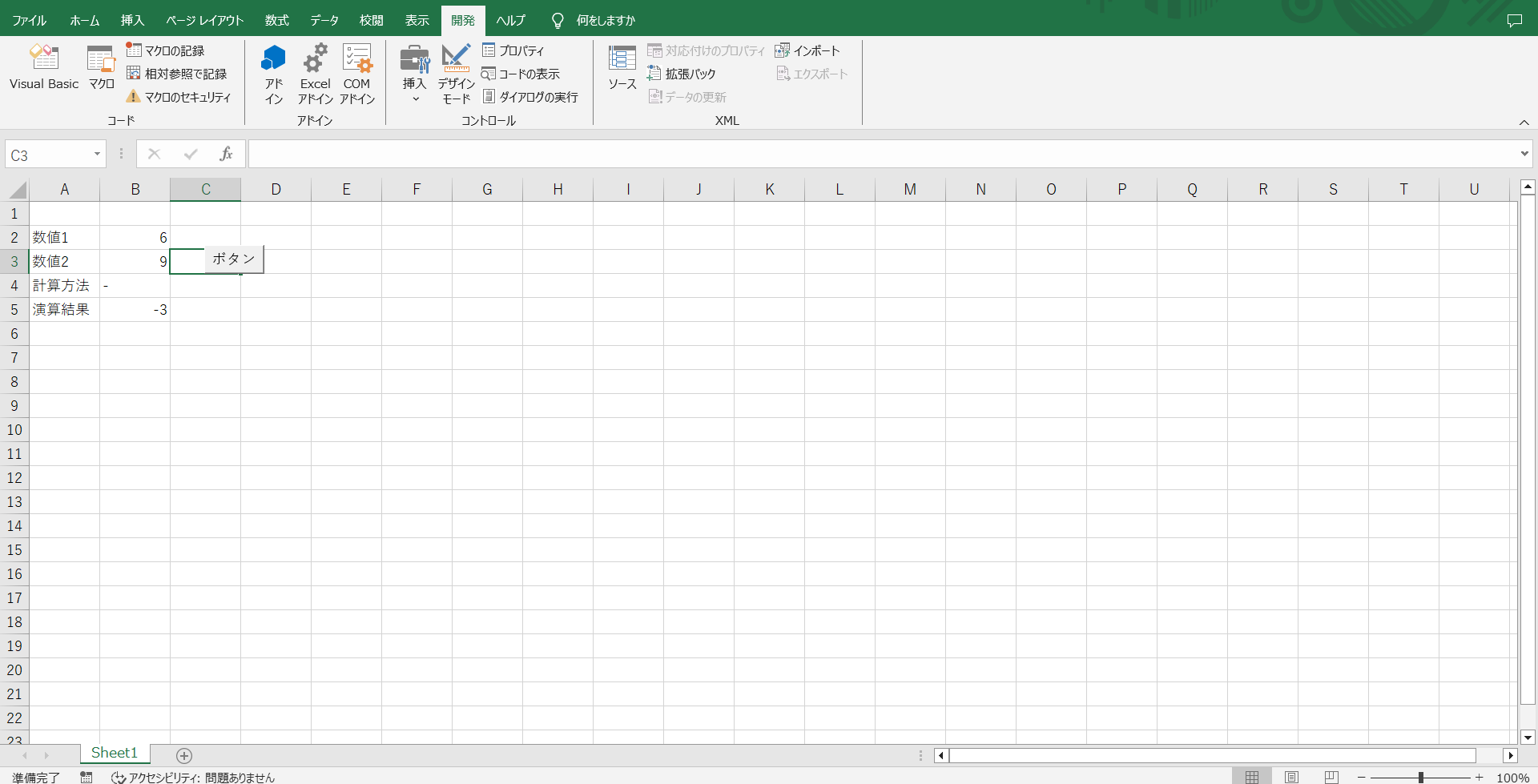
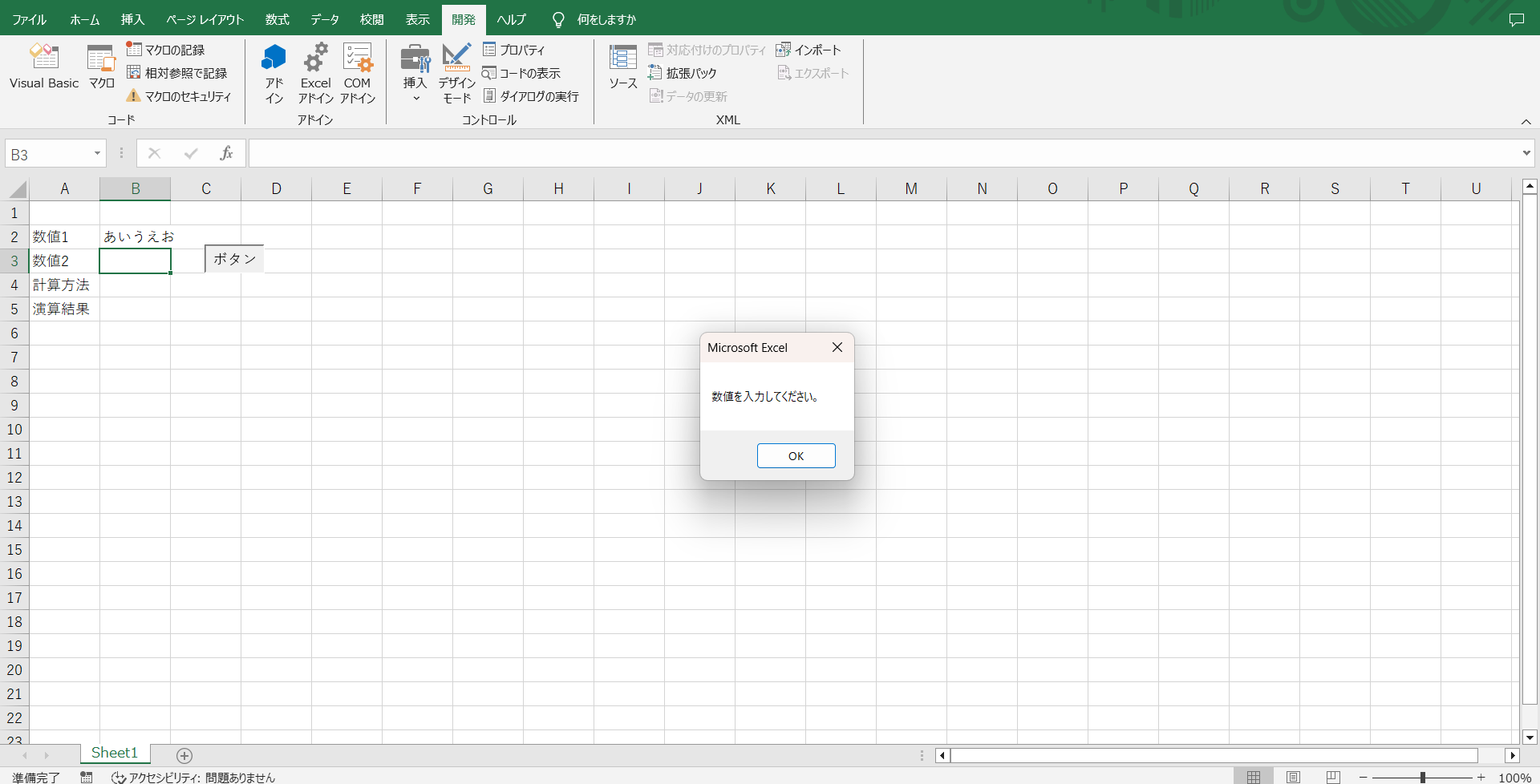 ちゃんとメッセージも表示されていますね。これで入力エラーになる心配はなさそうです。
ちゃんとメッセージも表示されていますね。これで入力エラーになる心配はなさそうです。