Excel上で、以下のようなフォーマットを見たことはあるでしょうか?
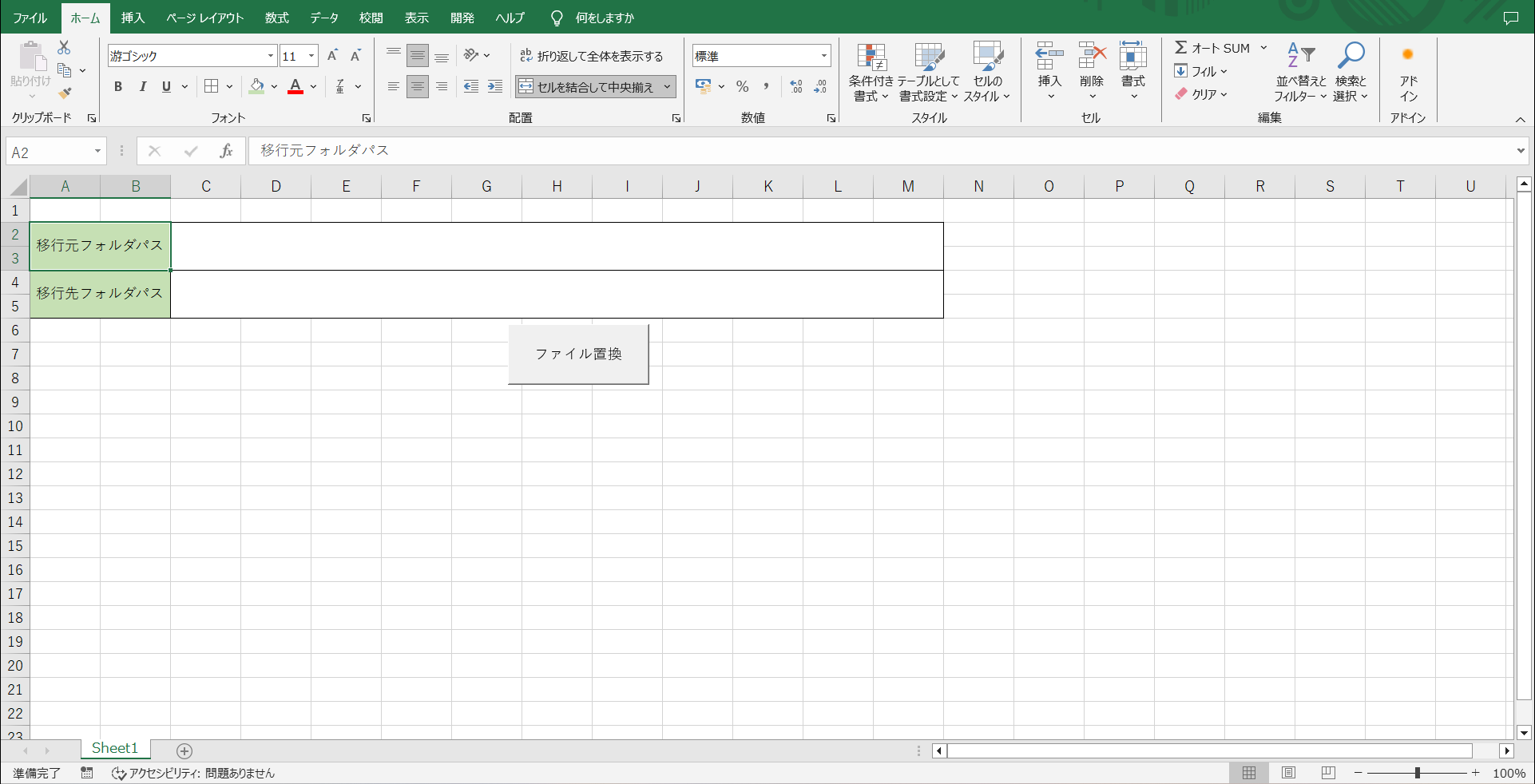 上記のフォーマットは、
上記のフォーマットは、
①「移行元フォルダパス」に置換したいExcelファイルが格納されているフォルダパスを指定
↓
②「移行先フォルダパス」に置換後のファイルを保存するフォルダパスを指定
↓
③「ファイル置換」のボタンを押下すると、置換対象のExcelファイルをもとに、別フォーマットに書き換えたExcelファイルを移行先フォルダパスで指定したフォルダに出力する
という一連の処理をマクロ化したExcelファイルになります。
このように、Excel上で特定の処理をマクロ化する際に使用する言語をVBA(Visual Basic for Application)といいます。
今回は、VBAを使うための初歩操作と、簡単なプログラムについて解説していきます。
VBAエディタ(VBE)の開き方
VBAを書き込むエディタ「VBE(VisualBasicEditor)」を開く方法は、以下の2通りがあります。
①Ctrl+F11を押下
②「開発」タブから「Visual Basic」を押下(「開発」タブについては、オプションからタブ上に表示させるように設定する必要があります)
上記方法でエディタを開くと、以下の画面になると思います。
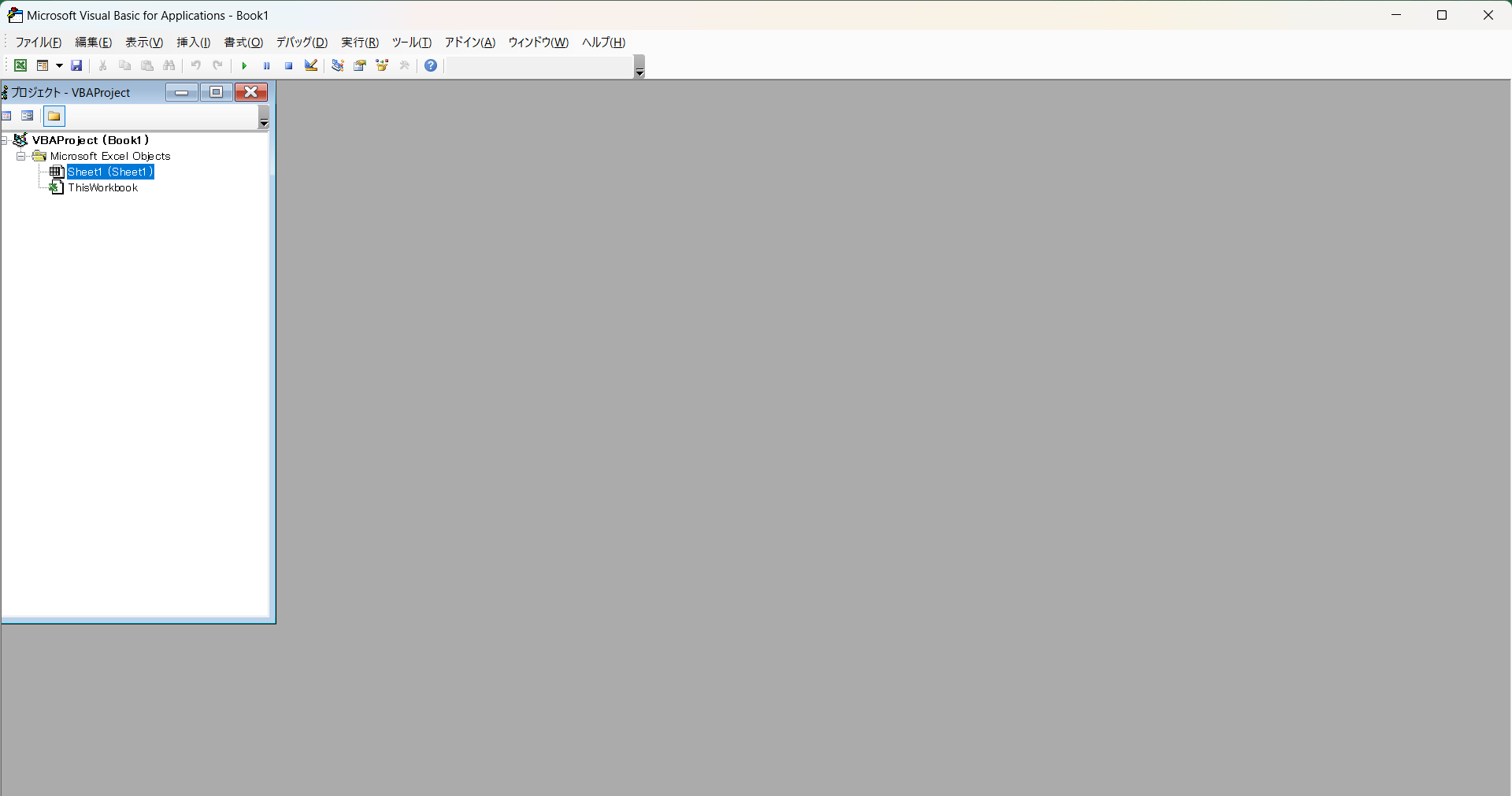 この画面のままではまだコードの書き込みは行えないので、モジュールを追加します。
この画面のままではまだコードの書き込みは行えないので、モジュールを追加します。
上記画面で、「挿入」タブ→「標準モジュール」を押下するとコードを書き込むウインドウが表示されます。
 次は、簡単なプログラムについて解説します。
次は、簡単なプログラムについて解説します。
足し算・引き算の処理を実行するプログラムを作る
ここからは、標準モジュール内にプログラムを書き込み、「セル内の数値を判定して足し算・引き算の計算結果を出力するプログラム」を作成していきます。
まず、モジュール内に「Sub <Sub名>()」を記載します。このSubは、他のプラグラミング言語でいうメソッドに該当します。
<Sub名>には、任意の名前をつけられます。日本語も使用可能なので、本記事では「足し引き処理」とします。
「Sub 足し引き処理()」を記入後、Enterを押すと末尾に「End Sub」という記載が自動的に追加されます。このEnd SubとSubの間に、行いたい処理を羅列していきます。
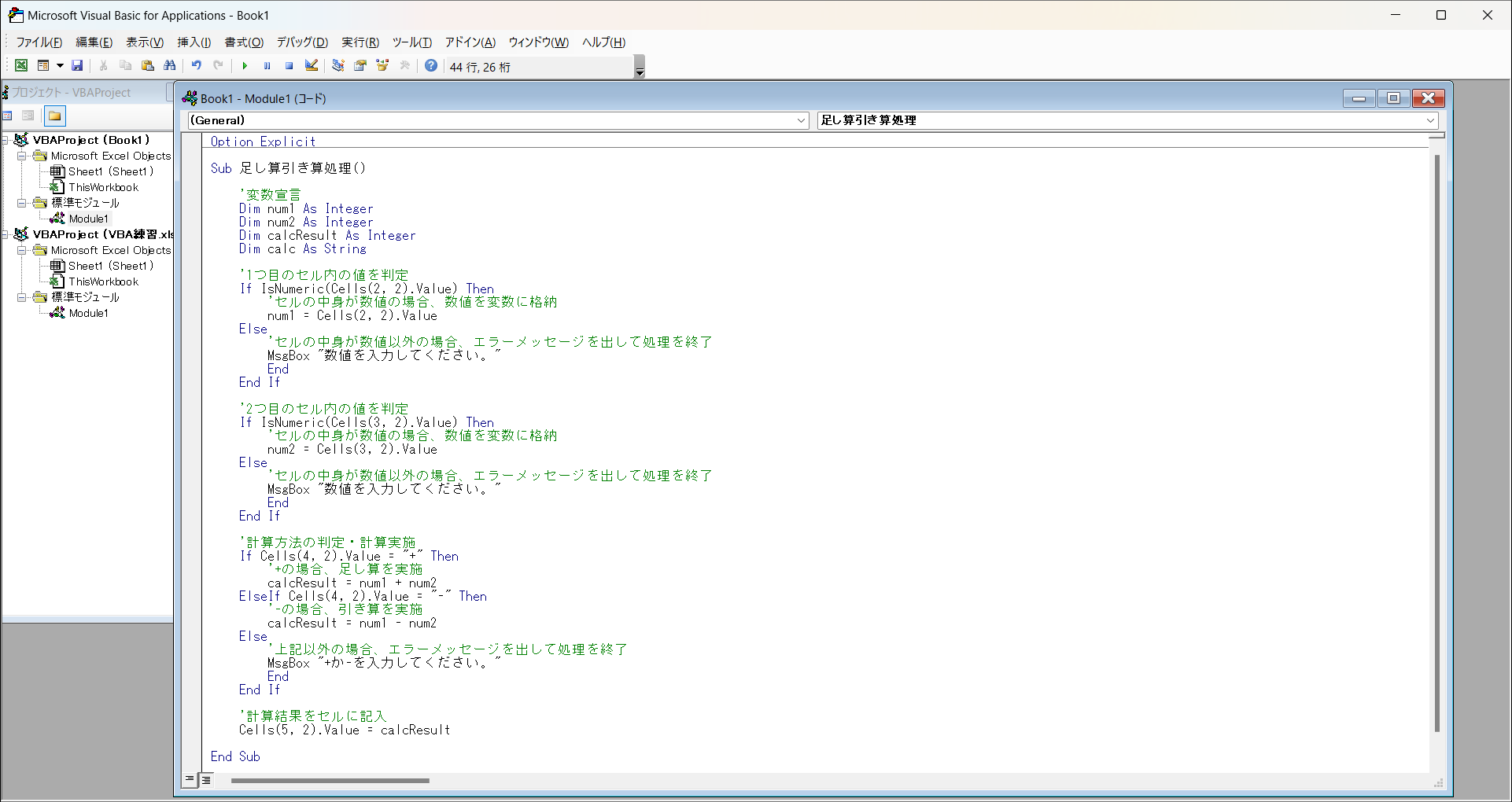
Sub内に、以下のコードを書き込みます。
Dim num1 As Integer
Dim num2 As Integer
Dim calcResult As Integer
Dim calc As String
上記コードは、処理内で使う変数の宣言になります。「Dim <変数名>」で変数名、「As <データ型>」でその変数の型を宣言しています。
今回は計算のプログラムなので、計算を行う数値を格納する変数を2つと、計算方法を指定するための変数を宣言しています。
次に、以下のコードを記入します。
'1つ目のセル内の値を判定
If IsNumeric(Cells(2, 2).Value) Then
'セルの中身が数値の場合、数値を変数に格納
num1 = Cells(2, 2).Value
Else
'セルの中身が数値以外の場合、エラーメッセージを出して処理を終了
MsgBox "数値を入力してください。"
End
End If
一個ずつ解説していきます。
2行目の「If <判定したい値・式> Then」は、<判定したい値・式>に記入した式や値が返す真偽の結果によって、処理を分岐させるためのステートメントです。Thenのあとには、判定結果がTrueの場合の処理を記載します。
「IsNumeric」は指定した値が数値かどうかを判定するための関数となります。今回は、セルの値を参照して数値かどうかを判定しています。
続いて、4行目の「num1 = Cells(2, 2).Value」は、先程宣言した変数の中にセルの値を格納しています。
Cells(行,列).valueは、セル内の値を参照しています。かっこ内の行と列については、どちらも数値で指定する必要があります。(列指定はA列から順に指定、E列を指定する場合は”5″になります)
今回は、B2に1つ目の数値を入力するため、Cells(2, 2)を指定します。
5~8行目は、1行目の条件分岐がFalseとなった場合の処理になります。
7行目のMsgBoxは、Excel上でメッセージボックスを表示させるための関数になります。MsgBoxのあとに、表示させたいメッセージを””(ダブルクォーテーション)囲みで記載します。
8行目のEndは、VBAの処理を途中で中断させる場合に用います。変数内に数値が入っていない状態で計算を行うと、予期しないエラーが発生する可能性があるため、セル内に数値以外が入力されている場合は、その時点で処理を中断させるようにしています。
こちらの処理は1つ目の数値に対する処理のため、2つ目の数値の処理も同じように記載します。
'2つ目のセル内の値を判定
If IsNumeric(Cells(3, 2).Value) Then
'セルの中身が数値の場合、数値を変数に格納
num1 = Cells(3, 2).Value
Else
'セルの中身が数値以外の場合、エラーメッセージを出して処理を終了
MsgBox "数値を入力してください。"
End
End If
こちらは、セルの取得範囲をB2からB3に変更したのみなので、説明は省略します。
次に、計算方法の判定を行う処理を記載していきます。
以下のコードを記載します。
'計算方法の判定・計算実施
If Cells(4, 2).Value = "+" Then
'+の場合、足し算を実施
calcResult = num1 + num2
ElseIf Cells(4, 2).Value = "-" Then
'-の場合、引き算を実施
calcResult = num1 - num2
Else
'上記以外の場合、エラーメッセージを出して処理を終了
MsgBox "+か-を入力してください。"
End
End If
2行目では、B4セルの値を取得して、特定の文字列であるかどうかの判定を行っています。今回は足し算or引き算を実施したいため、四則演算の記号”+”であるかどうかを判定します。
また、もし”+”でない場合でも、引き算であれば処理を実施したいため、5行目で四則演算の記号”-“であるかどうかを追加で判定しています。1つ目の条件がNGの場合に2つ目の条件判定を行いたい場合、ElseIfを記載します。
単純な計算を行う場合は、四則演算記号を使うのみで問題ありませんが、掛け算と割り算はプログラム上ではそれぞれ記号が異なるので注意してください。(今回は割愛します)
最後に、計算結果をセルに入力する処理を記載してプログラムは完成となります。
'計算結果をセルに記入
Cells(5, 2).Value = calcResult
完成したプログラムをExcel上で呼び出せるようにする
ここまでで計算を行うプログラムは完成しましたが、このままではまだExcel上から処理を行えないため、ここからはExcel上からプログラムを呼び出して処理を行えるようにする手順を紹介します。
まず、Excel上で「開発」タブ→「挿入」を押下してください。すると色々な図形が出てくるので、その中から「フォームコントロール」の長方形の図形(一番左上にあると思います)を選択します。
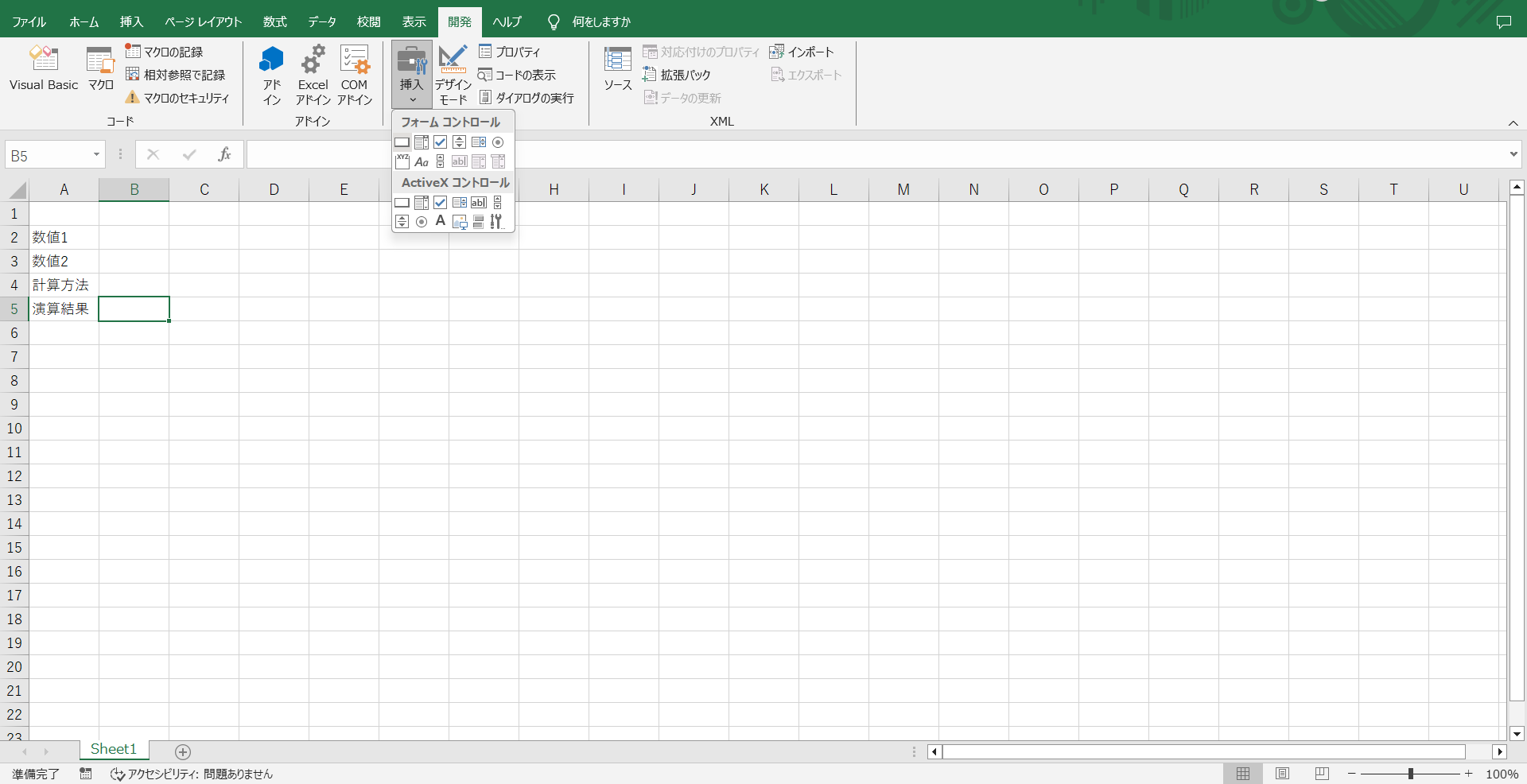
※VBAで指定したセルの箇所をわかりやすくするため、A列にそれぞれの値を記入しています
長方形を選択すると、カーソルが+状になると思うので、ワークシート上の適当な場所を選択します。
選択すると、マクロ登録ウインドウが出てくるので、こちらで先程作成した「足し引き処理」を選択します。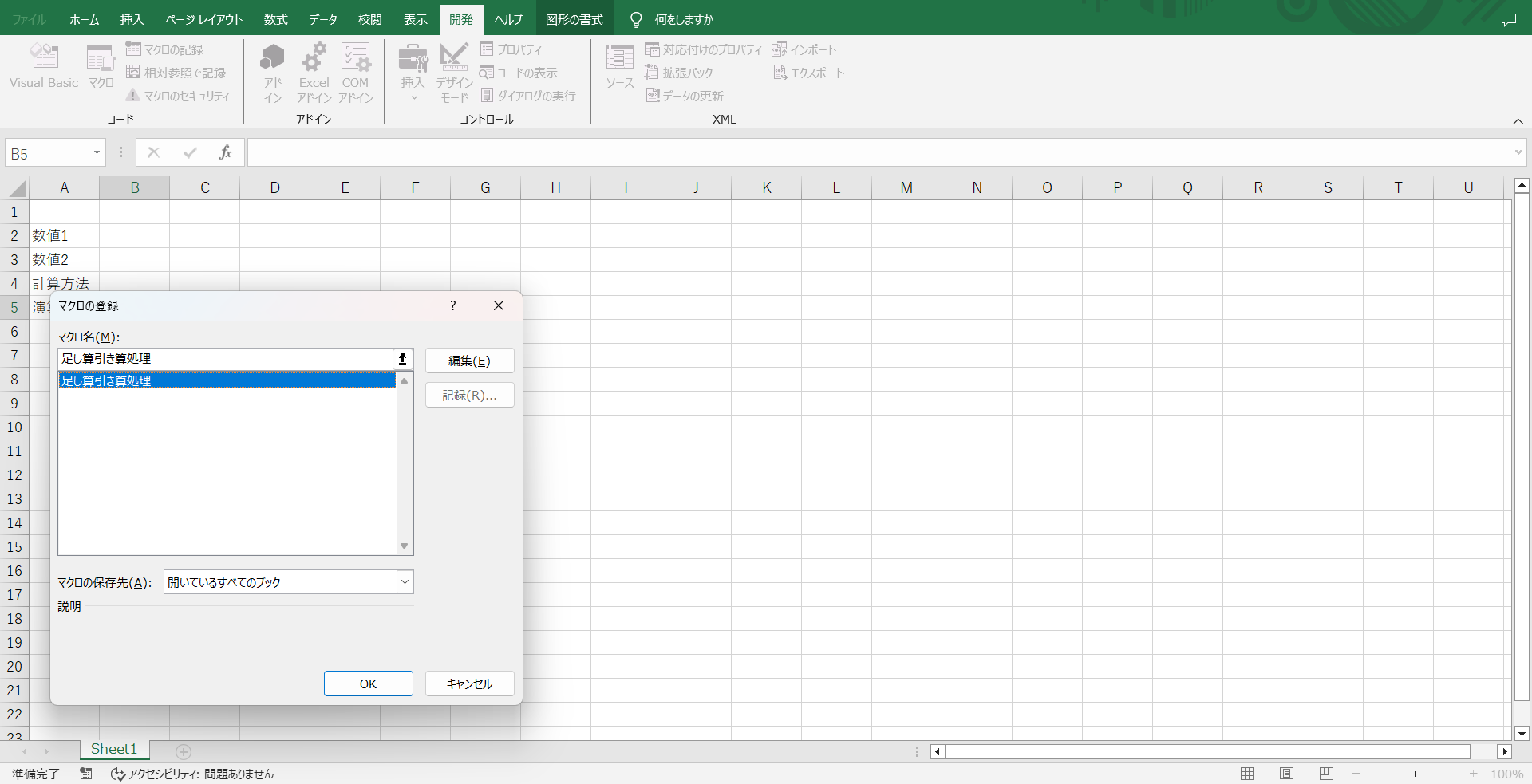
選択後、OKを押下すると「ボタン」と表示された長方形が生成されます。
こちらの長方形をクリックすると、「足し引き処理」に記述した処理が順次実施されます。
試しに、12+5の処理を実施してみます。B2セルに12、B3セルに5、B4セルに”+”を入力後、「ボタン」を押下してみます。
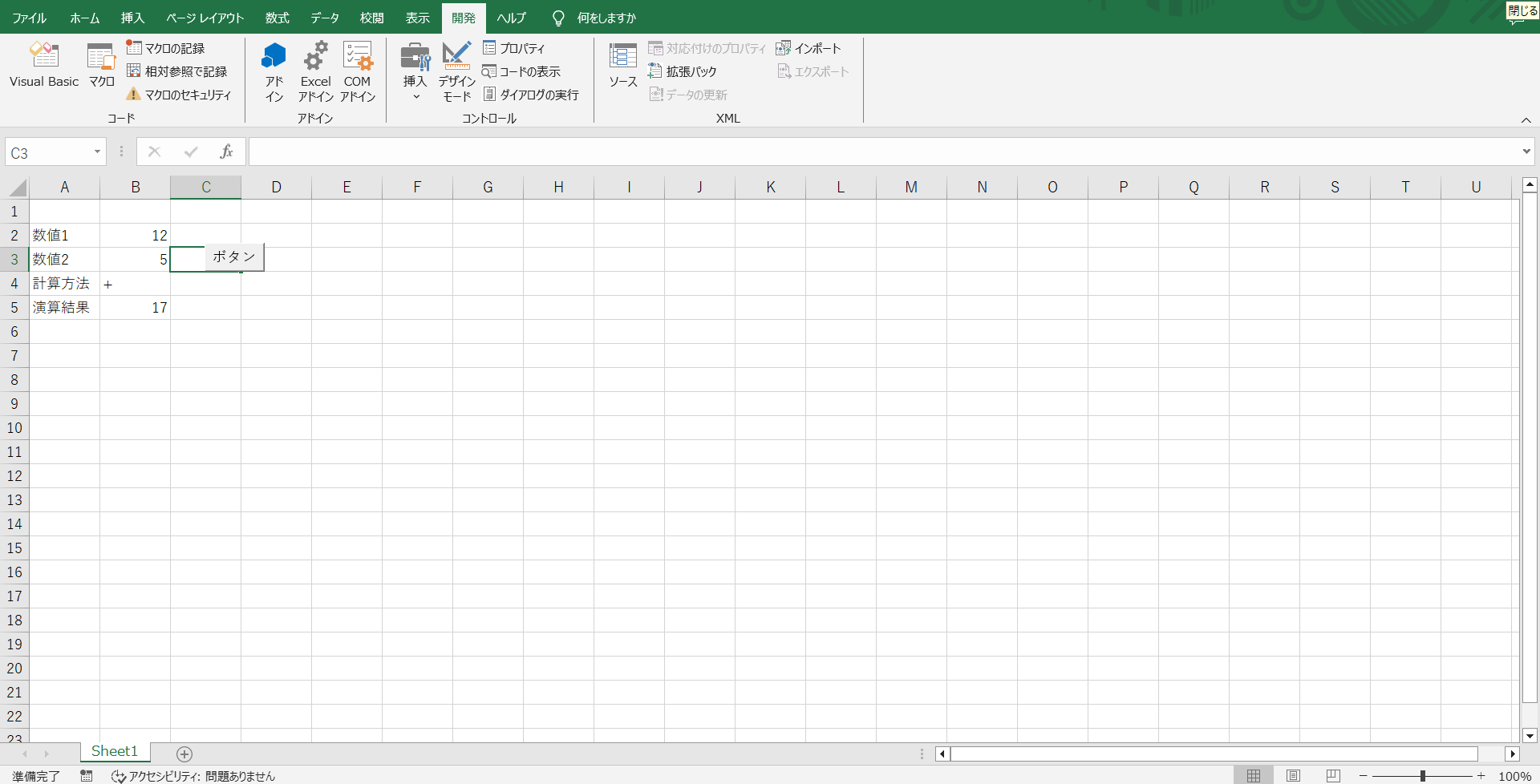 無事に計算結果である17が出力されました。
無事に計算結果である17が出力されました。
今度は、6-9を実施してみます。正常に動作すれば、-3になるはずです。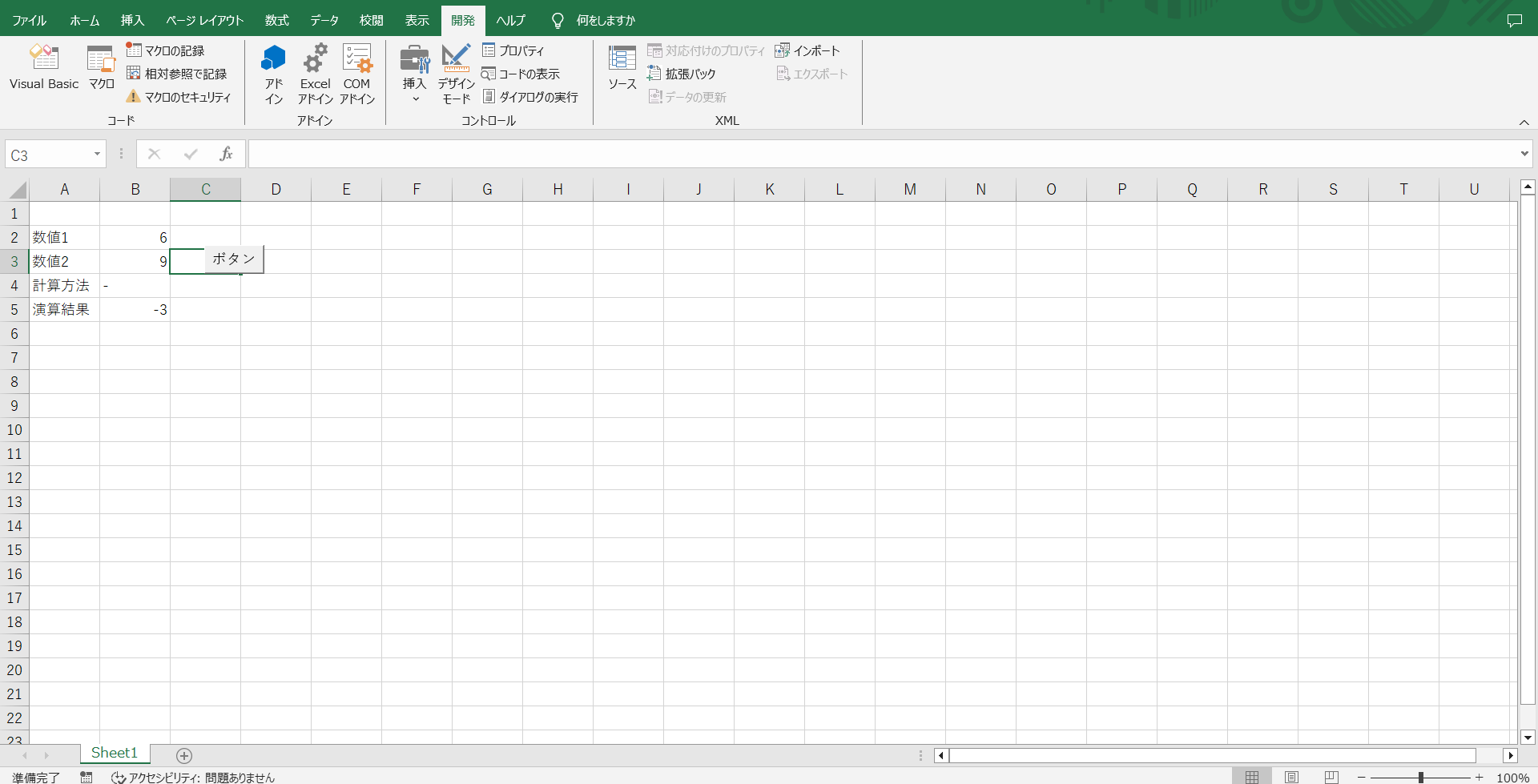
ちゃんと-3になりましたね。これで計算が正しく行われていることは確認できました。
最後に、想定しない入力が行われた場合にメッセージを表示させてくれるかを確認します。
数値1に”あいうえお”と入力してOKを押してみます。
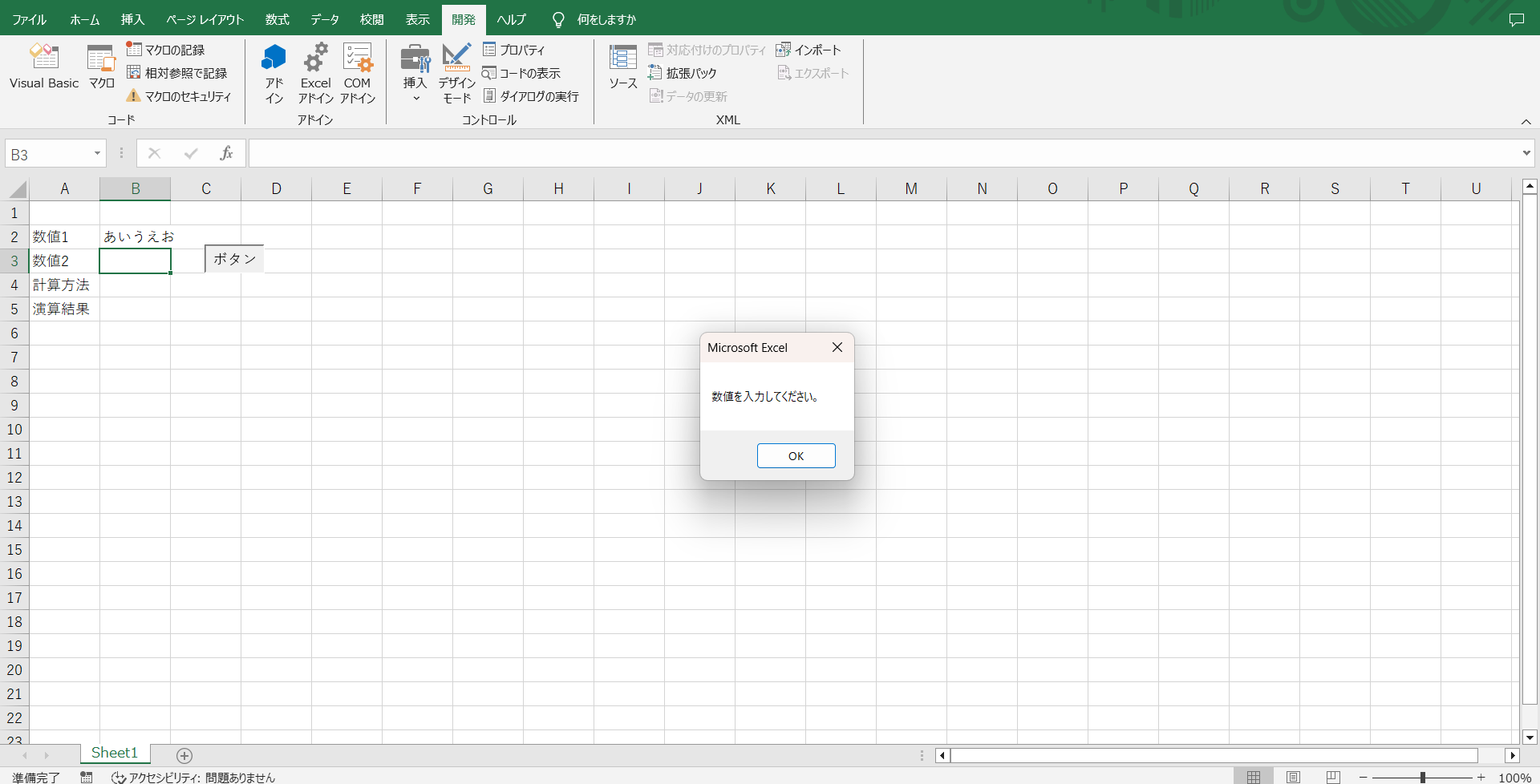 ちゃんとメッセージも表示されていますね。これで入力エラーになる心配はなさそうです。
ちゃんとメッセージも表示されていますね。これで入力エラーになる心配はなさそうです。
今回は、VBAの基礎を解説しました。かなり簡単なプログラムでしたが、もう少し複雑なプログラムを組むと、「シートの入力内容を別シートに書き移す」などの処理も自動化できるので、もしよろしければ是非VBAについて詳しく調べてみてください。

 無事に文字を表示することができました。
無事に文字を表示することができました。